I recently came across this /r/dataisbeautiful post and was wondering what the equivalent would look like using Australian stocks. I found historical market cap data for the ASX 200 and using D3 created a similar visualisation, experimenting with D3’s transitions, scales, areas and axis. Source code on GitHub.
Author: avin
-
Websockets are easy
I was interested in getting a minimal example working for Websockets and it was surprisingly easy to get a demo working between Node.js and a browser.
First install the
wslibrary:npm install wsCreate an
index.jsfile with the contents:const WebSocket = require('ws'); const wss = new WebSocket.Server({ port: 8080 }); wss.on('connection', function(ws) { console.log('Starting connection'); ws.on('message', function(message) { console.log('Received message: ' + message); ws.send('You sent ' + message); }); });Start the Node.js process:
node index.jsIn a browser console, send a message to the Node.js process:
var ws = new WebSocket("ws://localhost:8080"); ws.onmessage = function(e) { console.log(e.data); } ws.send('Hello World'); -
Re-rendering map layers
I recently was optimising the performance of a Leaflet-based map that rendered TopoJSON layers via Omnivore. The layers were a visualisation using the ABS’s Postal Areas, and while there was only a single TopoJSON file, this resulted in a number of feature layers being displayed, with each bound to their own data. The data for each feature layer could change depending on what filters were set (these filters were displayed in a left panel).
In the original implementation, whenever a change was made to a filter, the entire TopoJSON layer was removed, and then re-joined to the data set and rendered:
var dataLayer; function renderDataLayer() { var prevLayer = dataLayer; dataLayer = L.geoJson(null, { filter: filter, style: style, onEachFeature: onEachFeature }); omnivore .topojson('postal_areas.topojson', null, dataLayer) .on('ready', function() { // Remove previous layer when current layer is ready to avoid flickering if (prevLayer) { prevLayer.remove(); } }) .addTo(map); }Using Chrome’s “Record JavaScript CPU Profile”, it clearly showed the code invoking Omnivore was the problem:
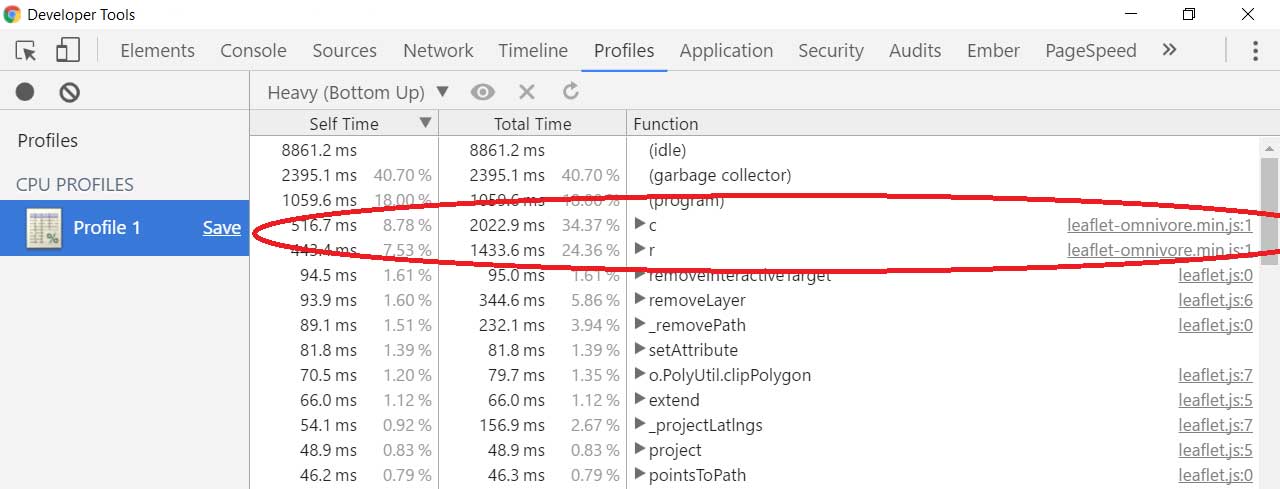
Changing the render function to (1) iterate over the existing layers and (2) change the style of the layer, made the map feel a lot more responsive.
var dataLayer = omnivore.topojson('postal_areas.topojson', null, dataLayer); function renderDataLayer() { dataLayer.eachLayer(function(featureLayer) { featureLayer.setStyle(style(featureLayer.feature)); }); }One of the disadvantages was that we can’t use the filter function on the
geoJsonobject anymore, since in order for a style change to occur, the feature layer must be present (although it can be hidden). This potentially can lead to slowness when dragging or zooming a map.Another related disadvantage is hiding layers both visually and from mouse events. Setting the
opacityandfillOpacityof the layer to 0 will take care of the first, while this CSS will prevent the mouse cursor from changing when hovering over a hidden layer:/* Don't show pointer on hidden layers */ .leaflet-pane > svg path.leaflet-interactive[stroke-opacity="0"][fill-opacity="0"] { pointer-events: none; } -
Templated SQL
I’ve recently been working on a data migration SQL script that performs the same operations against numerous tables. While I could use dynamic SQL – where SQL statements are built as a string and then executed – I don’t particularly like the downsides:
- It cannot be checked at compile time
- It is difficult to read, debug and reason about
- I’d have to use a cursor to iterate through each of the table names
Since this was a one-off migration task, I decided to render the SQL dynamically ahead of time and wrote a little utility in Node.js. So the template contained the SQL statements I wanted to execute, while the data contained a single column with the table names. For example:
data.csv
table tblA tblB tblC
template.mst
ALTER TABLE {{table}} ADD col VARCHAR(50);Output
ALTER TABLE tblA ADD col VARCHAR(50); ALTER TABLE tblB ADD col VARCHAR(50); ALTER TABLE tblC ADD col VARCHAR(50);
Wrap the output in a BEGIN/COMMIT TRANSACTION and we’re done.
-
Leaflet and Google Maps
I’ve recently been developing an application that uses Leaflet to interactivity with a geographic map. One of the business requirements was to use Google Maps as a basemap, since it is pervasively used by our customers. A naive implementation used Leaflet’s
tileLayerto render the tiles directly:var map = L.map('map').setView([-29, 133], 4); L.tileLayer('https://maps.googleapis.com/maps/vt?pb=!1m5!1m4!1i{z}!2i{x}!3i{y}!4i256!2m3!1e0!2sm!3i349018013!3m9!2sen-US!3sUS!5e18!12m1!1e47!12m3!1e37!2m1!1ssmartmaps!4e0').addTo(map);This approach, while simple, does not conform to the Google Maps API Terms of Service. Section 10.1.a indicates that:
No access to APIs or Content except through the Service. You will not access the Maps API(s) or the Content except through the Service. For example, you must not access map tiles or imagery through interfaces or channels (including undocumented Google interfaces) other than the Maps API(s).
To conform with the Terms of Service, I initially tried using leaflet-plugins, which creates a layer using the Google Maps Javascript API. However, when panning the map, the Google Map tiles lag compared to vector layers (e.g. polylines, polygons). This is a known, but unresolved issue and occurs because the Google Map
setCentermethod is asynchronous and thus will get out of sync with the Leaflet controlled elements.I next used a wrapper around leaflet-plugins. The wrapper (1) hides the leaflet-plugins Google layer and (2) finds the right tile image in the DOM (rendered by leaflet-plugins) and renders it when it becomes available. Here is a simplified example:
var GoogleGridLayer = L.GridLayer.extend({ // googleLayer is a leaflet-plugins Google object initialize: function(googleLayer) { this.googleLayer = googleLayer; }, onAdd: function(map) { L.GridLayer.prototype.onAdd.call(this, map); map.addLayer(this.googleLayer); // Hide the leaflet-plugins layer $(this.googleLayer._container).css("visibility", "hidden"); }, onRemove: function(map) { L.GridLayer.prototype.onRemove.call(this, map); map.removeLayer(this.googleLayer); $(map._container).find("#" + this.googleLayer._container.id).remove(); }, createTile: function(coords, done) { var img = L.DomUtil.create("img"); var googleLayer = this.googleLayer; var interval = setInterval(function() { var src; var id = "#" + googleLayer._container.id; var googleImg = $(id + " .gm-style img").filter(function(i, el) { var src = $(el).attr("src"); return src.indexOf("!1i" + coords.z + "!") > 0 && src.indexOf("!2i" + coords.x + "!") > 0 && src.indexOf("!3i" + coords.y + "!") > 0; }); if (googleImg.length) { googleImg = googleImg.first(); src = googleImg.attr("src"); } if (src) { clearInterval(interval); img.src = src; done(null, img); } }); return img; } });This approach seems to work reasonably well and is as responsive as the original tile layer implementation.
Other enhancements I added later were:
- Caching the image src rather than having to poll the DOM on every create tile request
- Adding support for Satellite and Hybrid maps (the latter requires a
divwith two nested images – one for the Satellite tile and one for the labels/roads tile) - Adding a timeout to polling – there are certain tile requests by Leaflet that aren’t fulfilled by the Google tile layer. It may be that Leaflet tries to load tiles past the viewport
- Adding attribution (including logo and copyright) by moving some of the
.gm-styleelements in front of theGoogleGridLayer. The Google Map stores a reference to these elements and appropriately changes their content.
One of the disadvantages at this stage is that there is no easy method to access Street View coverage tiles without simulating a drag of the Pegman. It would be nice if the Google Maps Javascript API supports a function to turn on/off the Street View coverage tiles.
-
Organise photos by date
I organise my photos by grouping them in a directory, where the directory takes on the name “created_date title” (e.g. 2016-05-16 Birthday Party). As it became tedious to create a directory and manually group photo sets, I wrote a Ruby script to assist with the heavy lifting. After that, it’s just a matter of providing a title to each created directory.
require 'exifr' require 'fileutils' Dir['*.jpg'].each do |file| date = EXIFR::JPEG.new(file).date_time if date folder = date.strftime('%Y-%m-%d') FileUtils.mkdir_p(folder) unless File.directory?(folder) FileUtils.mv(file, folder) end endNote: you will first need to run
gem install exifrto install dependencies. -
SecurePay SecureFrame example
I recently had to debug an application that uses SecurePay as an online payment system. Rather than using API integration, the application used SecureFrame, where SecurePay provides the payment page (e.g. via an
iframe). I couldn’t find an example in the SecureFrame documentation, so here’s a minimal working example:[pyg l=html]
[/pyg] -
Resetting password of Devise user from the database
I recently encountered a situation where I was trying to access a Rails application but:
- I didn’t know the password for the admin user
- The reset password functionality was not working
- I had no access to a Rails console
Knowing the User model was using Devise, I set a password for a user on a dev environment to find the
encrypted_password:u = User.find(1) u.update(password: 'password') u.encrpyted_password => "$2a$10$qjBArbMLISBaUDMKdNM0KuZNPsRzPMIINMsPT.NhE9UrIYnErVF2S" [/pyg] I could then use SQL to update the password on the prod environment: [pyg l=sql] UPDATE users SET encrypted_password = '$2a$10$qjBArbMLISBaUDMKdNM0KuZNPsRzPMIINMsPT.NhE9UrIYnErVF2S' WHERE id = 1;
-
Spatial Analysis with Python
I’ve recently had to undertake spatial data analysis and one of the more challenging tasks was to identify repeat vs unique vehicle journeys. While QGIS is fantastic for visualising routes through heatmaps and density plots, one of my requirements was to provide quantitative metrics around the proportion of repeat vs unique journeys.
To achieve this, I used several open-source Python tools:
- Fiona for importing the journey data stored as Shapefiles, represented as LineStrings
- Rtree for quickly identifying potentially relevant journeys through a geospatial index (to avoid calculating unnecessary and costly intersection operations)
- Shapely for calculating the intersection/difference between each journey and historical journeys
It took me several variations before I discovered an optimal solution, dropping the run time from 1+ day to under an hour. The lessons learned included:
- Preprocessing data to eliminate TopologyException: found non-noded intersection between LINESTRING
- Using an R-Tree to quickly eliminate geometry that is not overlapping the bounds of the geometry of interest
- Subtracting historical journeys (calculating the difference) from the current journey and determining the uniqueness, rather than finding the intersection of the current journey with the (cascaded) union of historical journeys to find “repeatness”
- Adding a tiny buffer to dramatically increase difference calculating speed (the LineString/Polygon difference operation is faster than LineString/LineString operation – at least for complex LineStrings)
Below is some representative code that illustrates the above methodology:
import fiona from shapely.geometry import mapping, shape from rtree import index INPUT = "journeys.shp" BUFFER_SIZE = 1 # Should be appropriate for the coordinate reference system of the INPUT file records = list(fiona.open(INPUT)) # Sort by date to identify "historical" routes records.sort(key=lambda record: record["properties"]["date"]) # Create indexes rtree_idx = index.Index() buffered_shape_cache = {} for pos, record in enumerate(records): shp = shape(record["geometry"]) rtree_idx.insert(pos, shp.bounds) buffered_shape_cache[record["properties"]["id"]] = shp.buffer(BUFFER_SIZE) for pos1, record in enumerate(records): current_geom = shape(record["geometry"]) current_geom_length = current_geom.length # Subtract all historical journeys for pos2 in rtree_idx.intersection(current_geom.bounds): # Only evaluate against historical journeys if pos2 ﹤ pos1: historical_geom = buffered_shape_cache[records[pos2]["properties"]["id"]] current_geom = current_geom.difference(historical_geom) if current_geom.length == 0: break remaining_length = current_geom.length print("id: {0}, length: {1}, remaining: {2}, proportion: {3}\n".format(record["properties"]["id"], current_geom_length, current_geom.length, current_geom.length / current_geom_length))If the entire data set is too large to load into memory, it can be partitioned (e.g. geometrically halved or quartered) and the results safely combined (based on id) to give an accurate proportion.
-
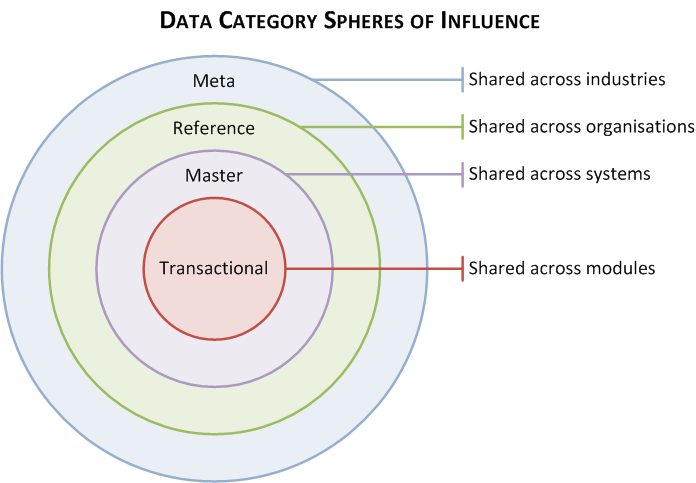
Data Category Spheres of Influence
I recently read the article “What is Master Data Management?” by Guy Holmes in the recent (Q2, 2015) PPDM Foundations Journal. There was one statement he made that thought-provokingly captured the definition of master data: “The key difference [from transactional data] is that master data elements tend to repeat in other data sets, and therefore consistency is key to quality”.
Differentiating transactional data from master data is a very common concept within the data management community. I also like to take it one step further and differentiate between master data and reference data, the latter being something that might “repeat” outside of an organisation, and therefore being a candidate for industry/international standardisation.
Continuing Guy’s line of reasoning: if (1) master data is shared across systems within an organization, and (2) reference data is shared across systems within an industry; then what category of data might be shared across systems but also across industries? Metadata?
I sketched a diagram around this thought, which indicates the “sphere of influence” of that data category – pragmatically, its applicability to be used/shared by systems.